Eating the Quadratic Elephant
The current recipe
Two papers, more than anything else, shaped how the modern AI industry is being built.
The first is the transformer paper (Vaswani et al., 2017), which gave us the architecture that powers basically every large model in production today. Its core primitive, self-attention, generalizes the attention mechanism originally introduced for neural machine translation a few years earlier (Bahdanau et al., 2015), where a decoder learned to softly align with the parts of the source sentence that mattered for each output word. The transformer’s move was to turn that mechanism on the sequence itself, drop the recurrence, and let every token attend to every other token directly.
The second is the OpenAI scaling-laws paper (Kaplan et al., 2020), which turned model-building into something close to engineering. The headline was simple: loss falls predictably as a smooth power law in model size, dataset size, and compute. Throw more of those at the same architecture and you reliably get a better model.
Together these gave enterprises a recipe (take the transformer, scale data and compute, get more intelligent systems), and that recipe is what accelerated the AI race. It also handed everyone the same bill. The elephant in the room is quadratic complexity in sequence length: every token a transformer generates has to look at every token before it, the cost grows as $O(n^2)$, and the memory you have to keep around for that lookup (the KV cache) grows linearly with context. For long sequences, reading that cache becomes the bottleneck, not the math itself.
The bet
The research direction I’m most excited about pushes against exactly this elephant: state-space models, linear RNNs, and linear attention. Three names, three histories, three sets of equations, but mathematically they are deeply interconnected, and the Mamba-2 paper (Dao & Gu, 2024) makes that unification explicit through what they call structured state-space duality. In all of them, generating each new token costs the same amount of compute and uses a fixed, compressed memory of the past.
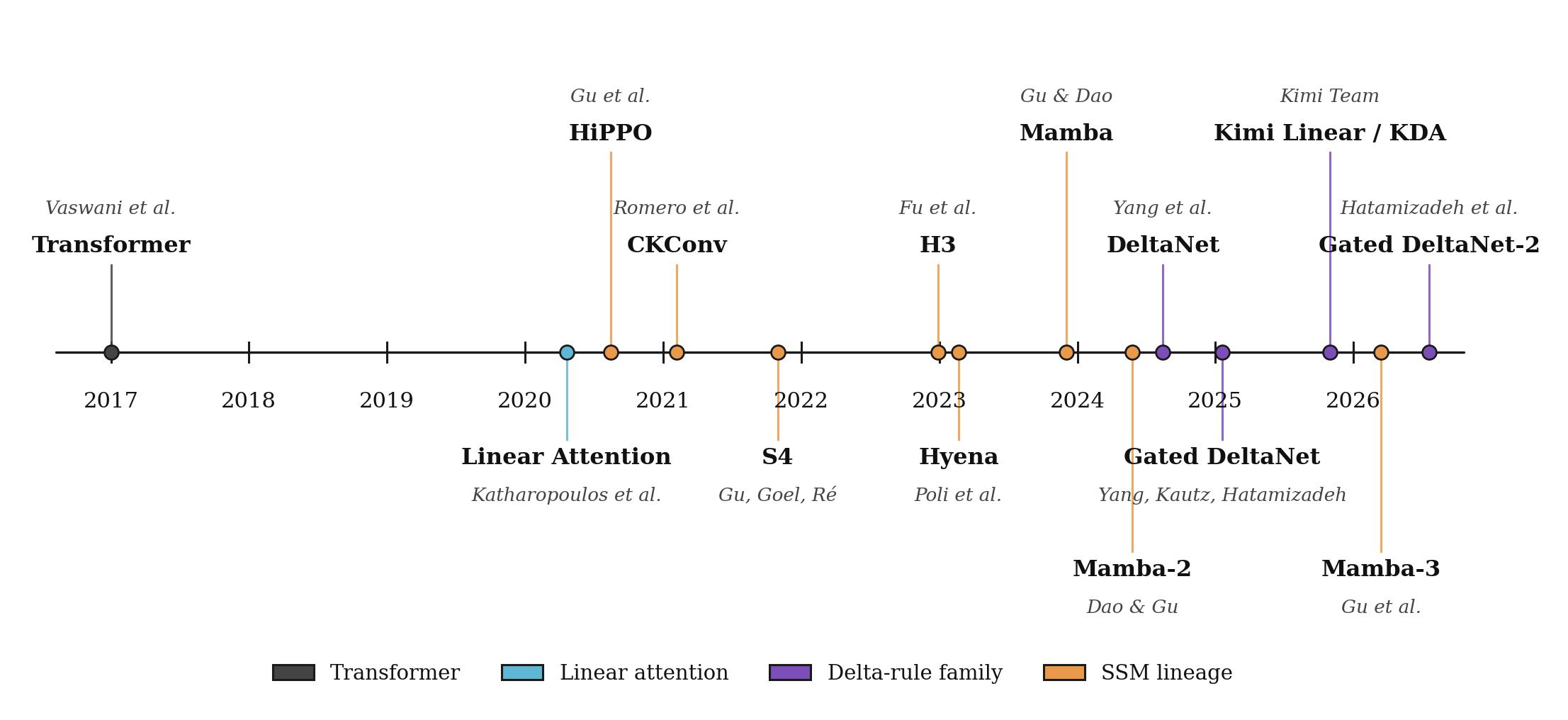
The state-space side of that lineage did not start with Mamba, or with deep learning at all. It traces back to Kalman (1960), A New Approach to Linear Filtering and Prediction Problems, the paper that introduced what is now called the Kalman filter. Kalman reformulated the classical Wiener filtering problem in state-space form (a hidden state $h_t$ that evolves linearly in time, observed through a noisy linear measurement) and derived a recursive estimator that updates the state optimally as each new observation arrives, under linear-Gaussian assumptions. It is the original example of a fixed-size summary of the past that gets cheaply updated one step at a time, and the state-space equations the Mamba family writes down are direct descendants of it. The modern deep-learning chapter then starts with HiPPO (Gu et al., 2020), which derives a principled way to compress a continuous-time signal into a fixed-size state by projecting it onto an orthogonal polynomial basis, essentially a mathematical answer to “what’s the best fixed-size summary of everything you’ve seen so far?” S4 (Gu, Goel & Ré, 2021) turned that compression theory into a practical deep-learning layer, with a clever structured parameterization of the state matrix that made long-range modeling actually tractable. CKConv (Romero et al., 2021) attacked the same problem from a different angle (continuous kernel convolutions) and ended up sibling to S4 in spirit. H3 (Fu et al., 2022) ported S4-style SSMs into a language-modeling stack and started closing the gap with transformers, and Hyena (Poli et al., 2023), essentially a mix of H3 and CKConv, replaced attention with long implicit convolutions in the same spirit. Each of these was a step toward a long-context model whose cost did not blow up with sequence length.
The first model in this line to seriously rival transformers was Mamba (Gu & Dao, 2023). Albert Gu and Tri Dao introduced a non-LTI (linear time-invariant) selective state-space model and, just as important, a hardware-aware algorithm that trained efficiently on modern GPUs. That second part is the part people undersell. The architectural idea had been floating around for a while; the win came from making it actually fast on the hardware everyone already had.
Where the quadratic cost comes from
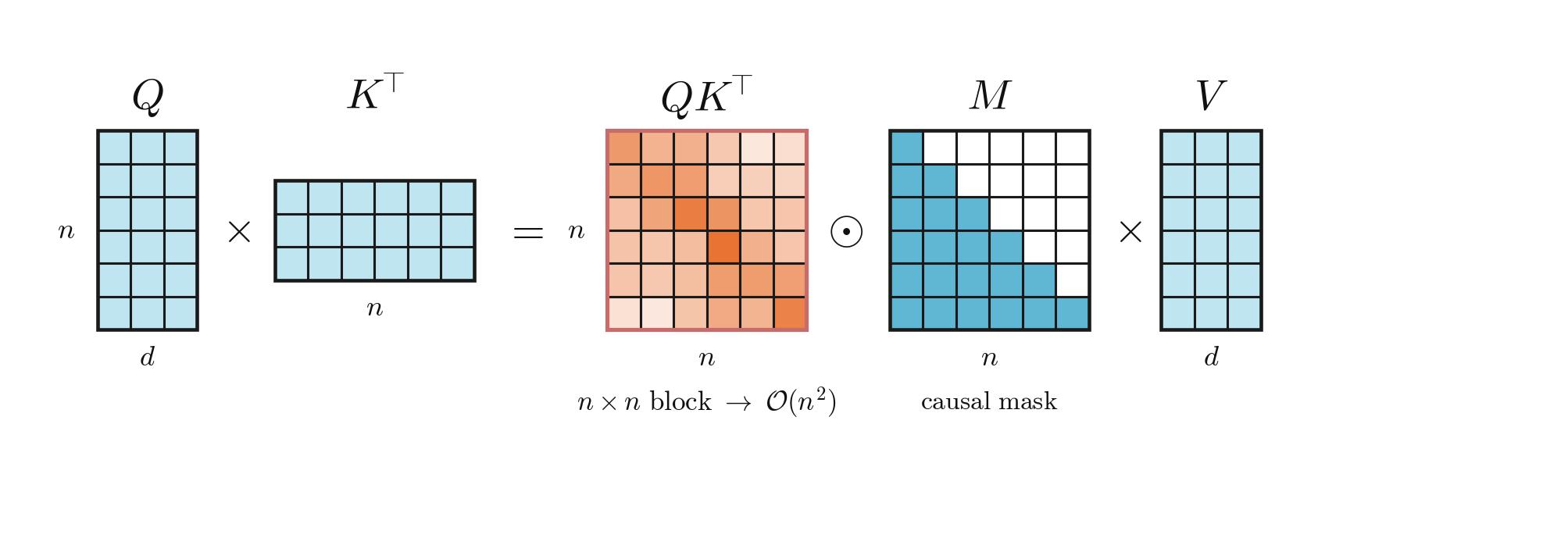
In standard attention you compute, for each new query $q_n$, a similarity score against every past key $k_i$, pass it through a softmax, and use the resulting weights to combine the values $v_i$. To do that during generation you have to keep every previous $(k_i, v_i)$ around. That’s the KV cache. Reading it scales linearly with context, computing the scores scales quadratically. At long context, the KV-cache reads are usually the bottleneck.
Deriving the linear form
If you drop the softmax (which is the lossy move at the heart of linear attention), something nice happens. For a query $q_n$:
$$ o_n = \sum_{i=1}^{n} q_n\,k_i^\top\,v_i = q_n \sum_{i=1}^{n} k_i^\top\,v_i $$
Group everything except $q_n$ into a single object:
$$ S_t = \sum_{i=1}^{t} k_i^\top\,v_i \;\in\; \mathbb{R}^{d_k \times d_v} $$
This $S_t$ is a fixed-size matrix that does not grow with context length. And because the sum is associative, it has a recurrent form:
$$ S_t = S_{t-1} + k_t^\top v_t \qquad o_t = q_t\,S_t $$
That is the trick. You have turned attention into an RNN whose hidden state is a matrix. $S_t$ is a compressed summary of everything that happened in the past, and at each step you add one rank-1 outer product to it. This is the view formalized in “Transformers Are RNNs” (Katharopoulos et al., 2020), the bridge paper that connected the two worlds.
SSMs (state space models)
The recurrence we landed on isn’t only an “RNN view of attention.” It is also exactly a state-space model (SSM), the same family of models that has been used in control theory and signal processing for decades.
Mamba 1 (Gu & Dao, 2023) writes a classical SSM in continuous form as
$$h'(t) = A\,h(t) + B\,x(t), \qquad y(t) = C\,h(t)$$
and, after discretizing the time step (e.g. via zero-order hold), as
$$h_t = \bar A\,h_{t-1} + \bar B\,x_t, \qquad y_t = C\,h_t$$
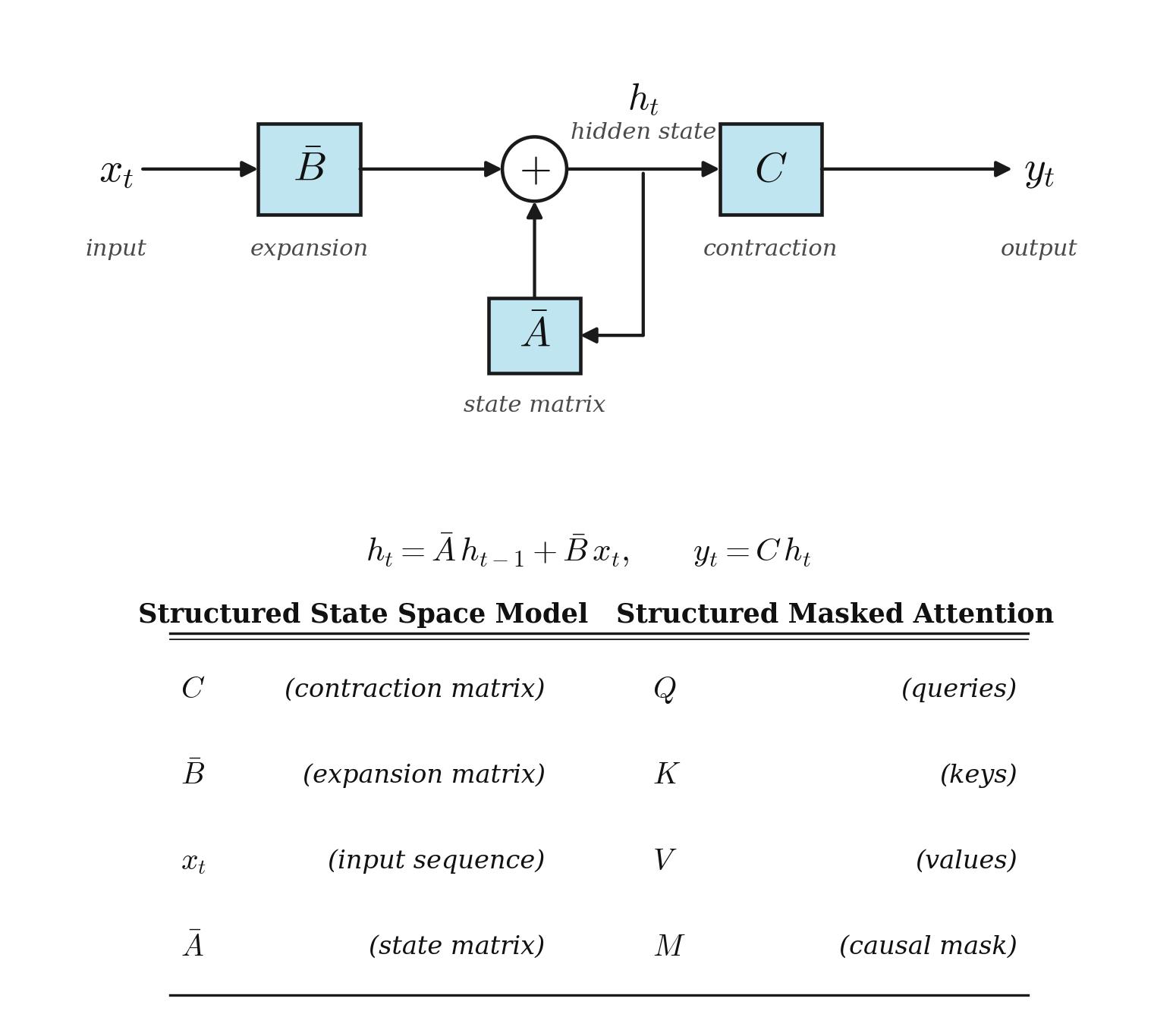
The picture is the same one we drew for linear attention. A fixed-size state $h_t$ rolls forward in time; $\bar A$ decides how much of the past survives; $\bar B$ decides how new input is written in; $C$ decides what gets read out.
Mamba 2 (Dao & Gu, 2024) makes the equivalence explicit. They start from exactly the move we used: drop the softmax and regroup the matmul,
$$(Q K^\top)\,V \;=\; Q\,(K^\top V)$$
and show that under a causal mask this expands into a recurrence whose state is the running sum $\sum_{i \le t} k_i^\top v_i$. In other words, the linear-attention update we already derived,
$$S_t = S_{t-1} + k_t^\top v_t, \qquad o_t = q_t\,S_t$$
is an SSM with $\bar A = I$, $\bar B\,x_t \mapsto k_t^\top v_t$ (rank-1 write), and $C \mapsto q_t$ (read). The only structural difference is that the state is a matrix rather than a vector, because each step writes a rank-1 outer product instead of a single input column.
Mamba 2 calls this structured state-space duality: there is one underlying object, and “linear attention” and “SSM” are two camera angles on it. The interesting differences show up the moment $\bar A$ is allowed to depend on the data, i.e. the moment the model gets to choose what to keep and what to forget at each step.
Key ingredients of SSMs
Once you write the model in this form, three design choices end up dominating everything else:
- State update. How does new information get written into $S_t$? Plain addition (as above) never forgets, which sounds nice, but in practice the state saturates and the model gets worse, not better, with longer context.
- Efficiency. Can the recurrence be parallelized over the sequence dimension during training (so you keep transformer-scale throughput) while staying recurrent at inference (so you keep linear cost)?
- State size. $S_t$ has fixed capacity. Whatever you fail to fit, you forget. This is the fundamental trade against transformers, which keep everything.
Most of the interesting work in this line is about knob 1. Once you stop pretending memory is free, the question becomes: what is the right rule for deciding what to write, what to erase, and what to keep?
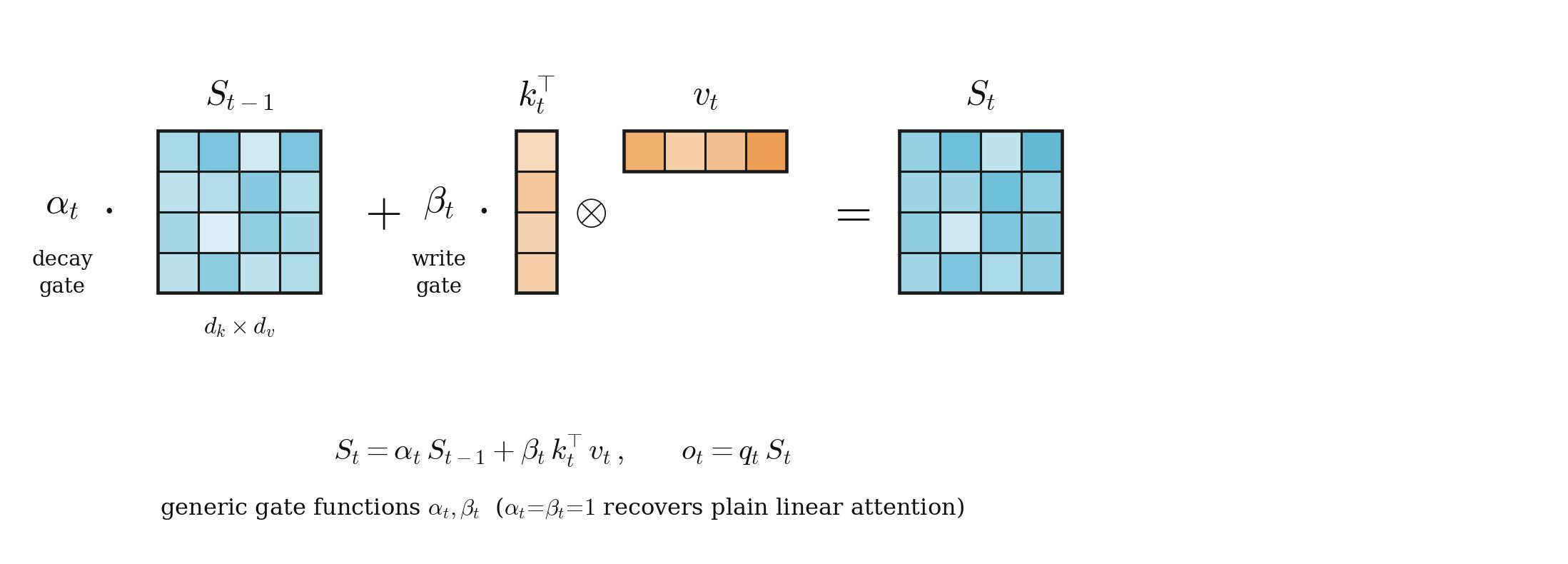
DeltaNet (Yang et al., 2024) introduced the delta rule: before writing new information for a key, first subtract the old value associated with that key, then write the new one. Concretely it replaces the naive addition with a “remove-then-write” step that stops the same key from accumulating conflicting writes.
Gated DeltaNet (Yang, Kautz & Hatamizadeh, 2024) added a learned gate on top, a per-token decay that lets the model decide when to write at all, and how aggressively to forget.
Recent work in this family pushes on the same underlying question from different angles. Gated DeltaNet-2 (Hatamizadeh et al., 2026), Kimi Linear / KDA (Kimi Team, 2025), and the parallel SSM lineage in Mamba-3 (Gu et al., 2026) all ask the same thing: how exactly should the state change from one token to the next?
That question is what the rest of this series is going to dig into.
One last note: there are many other key papers I did not include here that are absolutely relevant to this story. I left them out for length, not for importance. The honest summary is that a lot is happening on this axis right now, and I am very excited about how many innovations are coming in this direction.
Videos I found useful
-
 Beyond Softmax: The Future of Attention Mechanisms
Beyond Softmax: The Future of Attention Mechanisms
-
 MedAI #41: Efficiently Modeling Long Sequences with
Structured State Spaces
MedAI #41: Efficiently Modeling Long Sequences with
Structured State Spaces
-
 Beyond Transformers: Subquadratic Long-Context
Architectures
Beyond Transformers: Subquadratic Long-Context
Architectures
-
 Stanford CS25: On the Tradeoffs of State Space Models and
Transformers
Stanford CS25: On the Tradeoffs of State Space Models and
Transformers
-
 MAMBA-3 and State Space Models
MAMBA-3 and State Space Models
References
- Kalman, 1960. A New Approach to Linear Filtering and Prediction Problems. PDF
- Bahdanau et al., 2015. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv:1409.0473
- Vaswani et al., 2017. Attention Is All You Need. arXiv:1706.03762
- Gu et al., 2020. HiPPO: Recurrent Memory with Optimal Polynomial Projections. arXiv:2008.07669
- Kaplan et al., 2020. Scaling Laws for Neural Language Models. arXiv:2001.08361
- Katharopoulos et al., 2020. Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. arXiv:2006.16236
- Romero et al., 2021. CKConv: Continuous Kernel Convolution For Sequential Data. arXiv:2102.02611
- Gu, Goel & Ré, 2021. Efficiently Modeling Long Sequences with Structured State Spaces (S4). arXiv:2111.00396
- Fu et al., 2022. Hungry Hungry Hippos: Towards Language Modeling with State Space Models (H3). arXiv:2212.14052
- Poli et al., 2023. Hyena Hierarchy: Towards Larger Convolutional Language Models. arXiv:2302.10866
- Gu & Dao, 2023. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv:2312.00752
- Dao & Gu, 2024. Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality (Mamba-2). arXiv:2405.21060
- Yang et al., 2024. Parallelizing Linear Transformers with the Delta Rule over Sequence Length (DeltaNet). arXiv:2406.06484
- Yang, Kautz & Hatamizadeh, 2024. Gated Delta Networks: Improving Mamba2 with Delta Rule (Gated DeltaNet). arXiv:2412.06464
- Kimi Team, 2025. Kimi Linear (KDA). arXiv:2510.26692
- Gu et al., 2026. Mamba-3. arXiv:2603.15569
- Hatamizadeh et al., 2026. Gated DeltaNet-2. arXiv:2605.22791